
Lab Javascript/CSS

J'en convient, l'idée de vouloir faire pareille chose peut paraître farfelue. Et pourtant ! Quelle ne fût pas ma surprise, lorsque lors d'une intervention sur une application dont on m'avait innocemment caché les caractéristiques de l'hébergement, je me suis rapidement retrouvé face à l'erreur :
Fatal error: Call to undefined function: file_put_contents()
Et pareil constat avec sa consoeur :
Fatal error: Call to undefined function: file_get_contents()
Je crus d'abord à une farce. Puis à une restriction volontaire de l'hébergeur via la directive disable_functions, ne cessant néanmoins de me demander quelle obscure raison pouvait motiver cet acte de pur sadisme. Mais un rapide phpinfo() me révéla bien vite la triste réalité de la situation : j'étais là sur un antédiluvien serveur PHP 4.2, et ces fonctions aujourd'hui ô combien familières n'existaient tout simplement pas encore dans cette antique version du langage parue en 2002 !
Même si les statistiques mondiales collectées par w3techs.com (août 2013) permettent d'estimer qu'aujourd'hui moins de 3% des hébergements PHP fonctionnent encore en PHP 4 et que ce chiffre tend lentement vers 0 dans une longue agonie, voici malgré tout un patch permettant de rendre vie à ce couple de fonctions bien utiles. Bien conscient du peu d'intérêt qu'il pourra susciter, je le dédie spécialement au prochain Marty McFly du web qui se retrouvera tout comme moi propulsé dans une lointaine époque.
if (!function_exists('file_put_contents')) {
function file_put_contents($filename, $data, $flags=0, $context=null) {
$fopen_args = array(
$filename,
(($flags&FILE_APPEND) == FILE_APPEND) ? 'a' : 'w',
(($flags&FILE_USE_INCLUDE_PATH) == FILE_USE_INCLUDE_PATH)
);
if (is_resource($context)) {
$fopen_args[] = $context;
}
if (($fd = call_user_func_array('fopen', $fopen_args)) !== false) {
if (($flags&LOCK_EX) == LOCK_EX && !flock($fd, LOCK_EX)) {
fclose($fd);
return false;
}
for ($written=0, $l=strlen($data); $written < $l; $written += $nb) {
if (($nb = fwrite($fd, substr($data, $written))) === false) {
if (($flags&LOCK_EX) == LOCK_EX) {
flock($fd, LOCK_UN);
}
fclose($fd);
return false;
}
}
if (($flags&LOCK_EX) == LOCK_EX) {
flock($fd, LOCK_UN);
}
fclose($fd);
return $written;
}
return false;
}
}
if (!function_exists('file_get_contents')) {
function file_get_contents($filename, $use_include_path=false, $context=null, $offset=-1, $maxlen=-1) {
$fopen_args = array($filename, 'r', $use_include_path);
if (is_resource($context)) {
$fopen_args[] = $context;
}
if (($fd = call_user_func_array('fopen', $fopen_args)) !== false) {
if ($offset > 0) {
fseek($fd, $offset);
}
$buffer = '';
while (!feof($fd) && ($maxlen < 0 || ($r=$maxlen-strlen($buffer)) > 0)) {
if (($data = fread($fd, ($maxlen < 0 || $r > 8192) ? 8192 : $r%8192)) === false) {
fclose($fd);
return false;
}
$buffer .= $data;
}
fclose($fd);
return $buffer;
}
return false;
}
}
Au cours de mes recherches dans les profondeurs de la documentation PHP, il m'arrive assez fréquemment de rencontrer des anomalies diverses comme des prototypes de fonction incomplets, de grossières fautes d'orthographe ou des phrases à peine plus compréhensibles que celles générées par un traducteur automatique. Autant de détails dont l'importance peut paraître insignifiante mais qui contribuent à décrédibiliser le sérieux du langage. Et pourtant, en ingrat développeur que je suis, j'avoue n'avoir jamais pris la peine d'informer la communauté PHP de ces défauts, sombrant de jours en jours en peu plus loin dans le péché.
Jusqu'au jour où ma bonne conscience se réveilla, probablement illuminée par une intervention de notre bienveillant Dieu Rasmus, qui de tout là-haut ramène ses fidèles développeurs dans le droit chemin. Au cours de cette divine apparition, il me pardonna puis me rappela l'existence de son outil de rapport de bugs et insista sur le fait que les problèmes liés à la documentation y sont bien entendu acceptés, car tout bug est égal à son prochain.
Je me suis donc depuis lors acharné à signaler le moindre problème rencontré, et c'est ainsi plus d'une centaine de corrections qui ont été envoyées, approuvées puis appliquées à notre manuel chéri. Sans vouloir imiter Frédéric Hardy et ses Nouvelles du front, voici l'inventaire des modifications apportées aux prototypes de nombreuses fonctions :
#54747, #54748, #54749, #54750, #54751, #54752, #54753, #54754, #54755, #54756, #54757, #54761, #54762, #54763, #54768, #54770, #54771, #54772, #54773, #54779, #54780, #54781, #54782, #54783, #54784, #54785, #54786, #54787, #54788, #54789, #54790, #54793, #54794, #54795, #54796, #54797, #54800
Celles-ci, plus anecdotiques, concernent essentiellement des corrections orthographiques dans la documentation francophone et des erreurs relevées dans les scripts d'exemple.
#54806, #54807, #54808, #54809, #54810, #54811, #54812, #54813, #54814, #54815, #54816, #54817, #54818, #54819, #54820, #54822, #54823, #54825, #54826, #54827, #54828, #54829, #54830, #54833, #54834, #54835, #54836, #54837, #54838, #54839, #54840, #54841, #54845, #54846, #54847, #54848, #54849, #54850, #54853, #54854, #54855, #54856, #54857, #54858, #54868, #54869, #54872, #54873, #54874, #54875, #54876, #54877, #54878, #54879, #54880, #54881, #54882, #54883, #54884, #54885, #54886, #54887, #54889, #54890, #54891
Une démarche apparemment trop peu fréquente, puisqu'elle a suscité la curiosité de plusieurs membres éminents de la Documentation Team comme Peter Cowburn, Richard Quadling ou Pierrick Charron, visiblement soucieux de mon intégrité humaine. La méthode utilisée ne relève pourtant pas du miracle : j'ai simplement téléchargé le manuel au format HTML, puis à l'aide de quelques expressions régulières j'ai rapidement pu détecter les fautes d'orthographe ou de grammaire courantes. Je ne peux donc qu'encourager chaque développeur à participer, dès qu'il en a l'opportunité, à l'amélioration de ce formidable outil dont nous profitons tous égoïstement. Un simple acte citoyen suffit à témoigner de la reconnaissance envers les nombreux anonymes bénévoles dont les contributions nous furent, un jour ou l'autre, d'une aide plus que précieuse.
Dans la continuité du billet très intéressant de Vincent Battaglia consacré à l'utilité du système de numération hexatridécimal (soit en base 36) dans l'algorithme d'un raccourcisseur d'URL, j'ai voulu savoir si utiliser d'autres systèmes de numération encore plus vastes, comme le base 62 évoqué à la fin de son article, pouvait se faire avec autant de facilité, ce qui permettrait de générer des URL encore plus courtes à moindre effort.
Comme il l'a déjà bien expliqué, le principal critère qui influencera le choix entre l'une de ces deux bases est certainement le souci de la sensibilité à la casse. En effet, la base 36 se concentre sur le système alphanumérique minuscule tandis que la base 62 inclut aussi les caractères majuscules.
D'autre part, il va évidemment de soi qu'au plus la base est élevée (autrement dit au plus l'éventail de symboles possibles est vaste), au plus un nombre peut-être représenté de manière concise. Dans le cadre des raccourcisseurs d'URL, c'est donc aussi un critère primordial. Non seulement pour l'économie de caractères que cela implique, mais aussi pour le nombre d'identifiants que le service pourra gérer, et donc le nombre d'URL qu'il pourra prétendre offrir. Bien que la plupart des services actuels comme TinyURL, bit.ly ou goo.gl semblent s'être limités à une base 62, d'autres sont plus aventureux, comme par exemple le service (belge, disons-le !) http://ui.tl qui affirme être le plus concis du marché par l'utilisation d'une base 163, prenant ainsi le risque d'inclure des caractères accentués dans ses résultats.
Lors de la mise en pratique, je fus tout d'abord surpris de découvrir que la fonction base_convert de PHP ne supporte pas la conversion d'un nombre en base 62. L'occasion étant trop tentante, j'en ai profité pour réécrire une fonction sensiblement identique permettant cette fois de jongler entre différentes bases arbitraires avec une totale liberté.
Par la même occasion, j'y ai ajouté au travers d'un dernier paramètre optionnel la possibilité de spécifier le jeu de caractères à prendre en compte lors de la conversion. J'y vois plusieurs cas d'utilisation concrets, comme par exemple :
- Pouvoir déjouer le caractère prédictif inhérent à ce genre de conversion, en spécifiant un alphabet dont l'ordre aura été préalablement altéré.
- Pouvoir générer des valeurs "user-friendly", en omettant par exemple les caractères susceptibles de prêter à confusion lors de la lecture, tels o,O,0,1,l, etc...
- Pouvoir définir son propre jeu de caractères, qui pourrait par exemple inclure des caractères spéciaux.
/**
* Convertit un nombre entre différentes bases.
*
* @param string $number Le nombre à convertir
* @param int $frombase La base du nombre
* @param int $tobase La base dans laquelle on doit le convertir
* @param string $map Eventuellement, l'alphabet à utiliser
* @return string|false Le nombre converti ou FALSE en cas d'erreur
* @author Geoffray Warnants
*/
function base_to($number, $frombase, $tobase, $map=false)
{
if ($frombase<2 || ($tobase==0 && ($tobase=strlen($map))<2) || $tobase<2) {
return false;
}
if (!$map) {
$map = implode('',array_merge(range(0,9),range('a','z'),range('A','Z')));
}
// conversion en base 10 si nécessaire
if ($frombase != 10) {
$number = ($frombase <= 16) ? strtolower($number) : (string)$number;
$map_base = substr($map,0,$frombase);
$decimal = 0;
for ($i=0, $n=strlen($number); $i<$n; $i++) {
$decimal += strpos($map_base,$number[$i]) * pow($frombase,($n-$i-1));
}
} else {
$decimal = $number;
}
// conversion en $tobase si nécessaire
if ($tobase != 10) {
$map_base = substr($map,0,$tobase);
$tobase = strlen($map_base);
$result = '';
while ($decimal >= $tobase) {
$result = $map_base[$decimal%$tobase].$result;
$decimal /= $tobase;
}
return $map_base[$decimal].$result;
}
return $decimal;
}
Pour se faire une idée de l'allure que peuvent avoir les valeurs retournées par cette fonction, voici à titre indicatif les résultats d'une série de conversions entre différentes bases. En ce qui concerne la base 163, j'ai considéré le jeu de caractères revendiqué par le service http://ui.tl.
| base 10 | base 16 | base 36 | base 62 | base 163 |
|---|---|---|---|---|
| 100 | 64 | 2s | 1C | Æ |
| 1000 | 3e8 | rs | g8 | 'Ú |
| 10000 | 2710 | 7ps | 2Bi | e% |
| 100000 | 186a0 | 255s | q0U | %}I |
| 1000000 | f4240 | lfls | 4c92 | OIÌ |
| 10000000 | 989680 | 5yc1s | FXsk | $6Ô@ |
| 100000000 | 5f5e100 | 1njchs | 6LAze | @gÉ1 |
| 1000000000 | 3b9aca00 | gjdgxs | 15FTGg | #5Û#. |
| 10000000000 | 2540be400 | 4ldqpdk | aUKYOs | 6^/5Ç |
S'il fallait citer un plugin sans lequel le développement sous Notepad++ deviendrait une calamité, mon choix se porterait très certainement sur l'indispensable Function List, un explorateur de code qui vient se greffer à l'éditeur et ainsi l'enrichir d'un outil par défaut absent mais pourtant très prisé des développeurs habitués aux IDE tels Eclipse ou NetBeans.
Bien que l'idée paraisse alléchante, on découvre très vite que dans un environnement PHP orienté-objet, l'intérêt de ce plugin se révèle finalement assez limité, surtout sachant avec quelle précision les IDE actuels peuvent synthétiser la structure d'une classe. Function List se contente lui de lister les fonctions et méthodes de manière dépouillée et surtout sans aucune prise en compte des caractéristiques orientées-objet tels la portée des méthodes, leur niveau de visibilité, les variables membres, les constantes de classes, etc...
J'ai cependant découvert que la configuration par défaut du plugin n'est pas du tout prévue pour exploiter pleinement les possibilités offertes. En effet, le plugin reconnait les différentes structures de n'importe quel langage grâce à une collection d'expressions régulières parfaitement configurables. Celles qui concernent la syntaxe de PHP sont effectivement réduites à leur strict minimum.
Je me suis alors attardé à réécrire une configuration plus adaptée au développement orienté-objet en PHP. Inspiré par l'explorateur de code d'Eclipse, je suis arrivé au résultat suivant :



Voilà donc un lifting rajeunissant qui ne dépaysera pas trop les utilisateurs d'Eclipse pour qui les icônes choisies sont déjà familières. Pour les autres, ou à titre de rappel, en voici la signification :
Pour l'avoir adoptée depuis quelques temps, je trouve cette configuration plus agréable, même si elle provoque un effet désagréable inhérent aux limitations actuelles du plugin (dans sa version 2.1) : Le tri ne s'applique plus sur l'ensemble de la liste mais séparément sur chaque groupe d'éléments, ce qui est parfois déstabilisant. Si un courageux se sent d'attaque, le code du plugin est en open source (C++) ;-)
Dernière remarque pour ceux qui voudraient améliorer cette configuration, j'ai pu remarquer que le système d'interprétation des expressions régulières se comporte bizarrement. Il semblerait que ce soit une limitation de Scintilla (le composant sur lequel le plugin est basé) qui ne permette malheureusement pas de tirer profit de la pleine puissance des expressions régulières. Ceci alourdi l'écriture des règles et restreint les possibilités.
Pour installer cette configuration, copiez les fichiers FunctionListRules.xml et php.bmp dans le répertoire %APPDATA%/Notepad++/plugins/config ou %INSTALL_DIR%/plugins/Config selon que vous ayez choisi ou non d'utiliser %%APPDATA% lors de l'installation de l'éditeur. Attention que ceci va restaurer les règles par défaut pour tous les autres langages. Pour conserver vos éventuelles personnalisations, ne copiez que le noeud <Language name="PHP"> du fichier XML.
Téléchargement
La librairie GD forme aujourd'hui avec PHP un couple apprécié des développeurs web. Elle offre en effet un accès d'une grande simplicité aux traitements d'images, ces opérations obscures qu'on sait truffées de formules mathématiques et autres transformations matricielles, et qu'on devine par conséquent probablement gourmandes en ressources matérielles. Mais sait-on exactement jusqu'à quel point ? Pour ma part non, jusqu'à aujourd'hui...
Le graphique ci-dessous représente la quantité de mémoire vive consommée par un script lors de la création d'une ressource GD en fonction des dimensions de l'image traitée (ou plutôt de sa définition pour être exact)
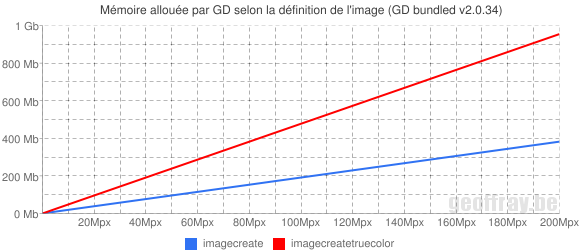
Comme on pouvait s'en douter, la mémoire requise est proportionnelle au nombre de couleurs ainsi qu'aux dimensions de l'image. On peut donc envisager qu'un fichier suffisamment imposant puisse saturer complètement la mémoire libre, celle-ci n'étant pas illimitée. Il en résultera alors un arrêt brutal du script causé par une erreur fatale (Fatal error: Allowed memory size of %d bytes exhausted (tried to allocate %d bytes)). Un sombre scénario qui, pour pouvoir être évité, doit d'abord être anticipé.
L'objectif de cette étude est donc d'estimer les dimensions maximales approximatives acceptables selon la configuration mémoire en vigueur. J'insiste sur le caractère approximatif car j'ai pu constater qu'à définition égale, la mémoire occupée par une ressource GD dépend aussi de ses proportions. Ainsi une image au format "portrait" (plus haute que large) risque de nécessiter d'avantage de mémoire que la même au format "paysage". Heureusement cette différence ne concerne de manière significative que des images étirées à l'extrême.
Voici donc les dimensions maximales estimées pour des images au format 4/3 :
| memory_limit | imagecreatetruecolor | imagecreate |
|---|---|---|
| 64M | 13 Mpx (~4162x3123) | 32 Mpx (~6532x4899) |
| 128M | 26 Mpx (~5889x4415) | 65 Mpx (~9308x6983) |
| 256M | 53 Mpx (~8406x6305) | 128 Mpx (~13064x9798) |
| 512M | 106 Mpx (~11887x8917) | 262 Mpx (~18689x14019) |
| 1G | 201 Mpx (~16372x12277) | 514 Mpx (~26179x19634) |
Ces valeurs permettent alors d'instaurer des vérifications adaptées aux contraintes mémoire en vigueur. Par exemple :
<?php
ini_set('memory_limit', '64M');
$size = getimagesize($filename);
if ($size===false || $size[0] > 4000 || $size[1] > 3000) {
throw new Exception('Image too large');
}
$rc = imagecreatetruecolor($filename);
Notons ici que le choix de la fonction getimagesize n'est pas anodin : elle permet d'obtenir les dimensions du fichier sans le charger entièrement en mémoire, ce qui n'est pas le cas par exemple de ses homologues imagesx et imagesy qui risquent de provoquer la saturation mémoire avant même d'avoir pu s'en prémunir...
Conclusion
La consommation mémoire des ressources GD n'est finalement pas si excessive. Les configurations standards permettent déjà de manipuler des images importantes sans soucis. Evidemment, je ne vous apprends rien en répétant que tout fichier externe doit être considéré comme une source de données potentiellement à risque, ce qui est d'autant plus vrai pour les images reçues par exemple au travers d'un formulaire d'upload, et qu'elles doivent donc toujours faire l'objet d'un contrôle minutieux avant d'être manipulées. Car une gestion correcte de la mémoire est avant tout du bon ressort du programmeur.
Malgré les considérables évolutions qu'a subi PHP, on ne peut nier qu'il est encore aujourd'hui trahi par de petites imperfections qui salissent son blason. Les détracteurs s'en donnent à coeur joie pour critiquer l'amateurisme du langage, les autres, certainement un peu fatalistes, préfèrent dire qu'il a le mérite d'être une source intarissable de surprises ;)
Dernière curiosité en date : La comparaison de 2 nombres décimaux n'est pas fiable. Ainsi :
var_dump(0.2+0.3 == 0.5); // affiche true var_dump(0.2+0.4 == 0.6); // affiche false
Le second résultat est pour le moins inattendu ! Il se comprend néanmoins en regardant de plus près la valeur réelle de chacune des valeurs jusqu'à leurs infimes décimales.
printf('%.20f', 0.2); // 0.20000000000000001110
printf('%.20f', 0.3); // 0.29999999999999998890
printf('%.20f', 0.2+0.3); // 0.50000000000000000000
printf('%.20f', 0.5); // 0.50000000000000000000
printf('%.20f', 0.2); // 0.20000000000000001110
printf('%.20f', 0.4); // 0.40000000000000002220
printf('%.20f', 0.2+0.4); // 0.60000000000000008882
printf('%.20f', 0.6); // 0.59999999999999997780
"Honteux" crierons les détracteurs, "normal" diront simplement les autres. En effet, un avertissement dans la doc PHP nous met en garde face à ce comportement hasardeux bien connu et l'explique par le fait que la représentation interne de certains nombres décimaux n'est pas possible sans une infime perte de précision. Une remarque qui n'est pas sans raviver mes lointaines notions d'ASM et les prises de tête pour comprendre la représentation des décimaux en binaire.
Bref, ce problème d'approximation est inhérent à nos ordinateurs. On le rencontre d'ailleurs dans d'autres langages de bas niveau, notamment en C, langage avec lequel est écrit PHP.
Que faut-il faire ?
Comme indiqué dans la doc, comparer des nombres décimaux de manière classique est à proscrire. Pour ce genre d'opération qui nécessite une précision importante, PHP fourni un ensemble de fonctions spécifiques, dont bccomp qui permet de comparer des nombres de grande taille.
var_dump(bccomp(0.2+0.4, 0.6)==0); // affiche true
Une autre solution plus artisanale consiste à caster les nombres en chaînes de caractères avant d'effectuer la comparaison.
var_dump((string)(0.2+0.4)==(string)0.6); // affiche true
Cette solution semble tout aussi acceptable puisque lors de la conversion, PHP prend soin de retirer les éventuels zéros non significatifs qui pourraient poser problème en cas de comparaison textuelle.
var_dump((string)(0.2+0.4)==(string)000.60000); // affiche true aussi
La suite n'est plus qu'une histoire de préférence...
Même si le système d'autocomplétion de fonction proposé par l'éditeur Notepad++ n'est pas pleinement satisfaisant, il propose néanmoins une option que je trouve fort utile : l'autocomplétion de paramètres. Elle permet d'afficher instantanément en infobulle le prototype complet de la fonction native qu'on est en train d'utiliser.

Pour l'activer, il faut se rendre dans le menu [Paramètrage]/[Préférences]/[Sauvegarde/Auto-complétion] et cocher la case [Afficher paramètres pendant la saisie]
Malheureusement, en ce qui concerne PHP, la base de données utilisée par l'éditeur semble dater de Mathusalem. De nombreuses fonctions n'y sont pas répertoriées, et pire encore pour être induit en erreur, certains paramètres sont parfois manquants, les types et les valeurs de retour ne sont pas toujours corrects, la plupart des valeurs par défaut ne sont pas mentionnées, de même que les passages par référence.
Je me suis donc attardé à reconstruire une base de données aussi "up-to-date" que possible. Elle est téléchargeable ici (dernière mise à jour le 16/02/2011) et doit être extraite dans le répertoire Notepad++/plugins/APIs/
Ce n'est pas dans mes habitudes d'annoncer la disponibilité d'une nouvelle version d'un logiciel, mais comme celle-ci m'est assez particulière, je me permets d'insister sur la release fraîchement sortie de PhpMyAdmin version 3.3.0.0. Cette version est effectivement une peu spéciale pour moi car c'est la première à intégrer officiellement ma maigre contribution au projet, à savoir une nouvelle fonctionnalité dont j'avais déjà parlé précédemment qui permet d'exporter les données d'une table MySQL sous forme d'un tableau PHP associatif.
J'ai donc eu l'honneur d'être cité dans dans le changelog de la release, dont l'extrait concerné figure ci-dessous. Une précision qui n'a bien entendu d'autre utilité que la postérité ;)
+ patch #2805828 [export] PHP array export plugin, thanks to Geoffray Warnants
Dans un environnement de développement normalement configuré pour afficher les erreurs de type E_NOTICE mais aussi E_STRICT, on se retrouve parfois confronté à une curieuse alerte, provoquée par une séquence d'instructions qui semble pourtant anodine.
Par exemple, pour extraire l'extension d'un nom de fichier, j'écris souvent de façon machinale :
$extension = end(explode('.', $filename));
Ce qui provoque une alerte assez déroutante :
Pour comprendre ce message, il faut d'abord se rappeler que la fonction end() accepte en réalité une référence de tableau, ce qui est tout à fait compréhensible puisqu'elle va le modifier en positionnant le pointeur interne sur son dernier élément.
Ensuite [1], il faut savoir que lorsqu'une fonction retourne une valeur, une variable temporaire est créée. Généralement, on récupère cette variable temporaire en l'assignant à une autre variable déclarée explicitement, mais dans notre cas, la variable temporaire retournée par la fonction explode() est directement transmise à la fonction end() qui, bien que ce soit effectivement un Array, la refuse et provoque l'alerte.
Ce comportement tout à fait légitime ne date pas d'hier. Il a été introduit en PHP 5.0.5 afin d'éviter des corruptions mémoires. On peut certainement mieux comprendre ce risque en se souvenant de la différence significative entre les pointeurs et les références du C++.
Selon Rasmus Lerdorf, fondateur de PHP, il est recommandé d'effectuer l'opération en deux étapes, en transitant par une variable déclarée.
$split = explode('.', $filename);
$extension = end($split);
Il souligne aussi à très juste titre que dans ce cas bien précis qui consiste en une opération fondamentale sur une chaîne de caractères, il est absolument injustifié de passer par un tableau pour résoudre ce problème alors que des fonctions spécifiquement dédiées aux chaînes de caractères suffisent. J'ajouterai même qu'elles seront aussi plus performantes !
$extension = substr(strrchr($filename, '.'), 1);
J'ai cependant découvert que la fonction current() ne provoque pas d'erreur avec une variable temporaire alors que son prototype signale aussi un passage par référence. On peut donc supposer, en sachant que current() ne modifie pas le pointeur interne du tableau, que le message d'erreur généré par PHP n'est pas tout à fait pertinent. Il devrait plutôt mentionner "Only variables should be updated by reference". Rasmus, si tu pouvais confirmer... ;)
Sachant cela, les fanatiques qui voudraient à tout prix s'en tirer avec une seule ligne de code peuvent toujours le faire, au prix d'une opération certainement assez coûteuse :
$extension = current(array_reverse(explode('.', $filename)));
Les problèmes de casting (transtypage) sont souvent considérés comme le propre des langages à typage fort tels que par exemple Java, C++ ou C#. L'upcasting (communément traduit en français par "transtypage vers le haut" ou encore "surclassement") consiste à transformer une classe dérivée en une classe dont elle hérite, lui faisant ainsi volontairement perdre de sa spécificité. C'est cette notion d'ascendance qui lui vaut le nom de casting vers le haut, par opposition au downcasting.
Bien que PHP ne puisse pas réaliser cette transformation nativement, voyons comme faire pour y remédier en imaginant l'exemple suivant :
class Person
{
}
class Child extends Person
{
}
Ainsi, avec une hiérarchie similaire écrite en Java, convertir une instance de Child en un objet de type Person aurait pu se faire tout naturellement.
Child c = new Child(); Person m = c;
Ce n'est malheureusement pas pareil en PHP, puisque comme l'indique la documentation sur le type casting, seule la conversion vers les types natifs est possible. La tentative suivante se solderait donc par une erreur de syntaxe.
$c = new Child(); $m = (Person)$c;
Pour remédier à ce problème, je m'inspire ici du concept de "constructeur de copie" qu'on retrouve en C++ et qui a pour but de réaliser une copie d'un objet via le constructeur de la classe. Bien souvent, la copie consiste tout bêtement en une initialisation dite membre à membre. On peut donc ajouter à la classe mère un constructeur jouant ce rôle :
class Person
{
/**
* Constructeur de copie
*/
public function __construct(Person $c=null)
{
if ($c !== null) {
foreach (get_object_vars($c) as $property => $value) {
if (!is_object($value)) {
$this->$property = $value;
} else {
$this->$property = clone $value;
}
}
}
}
}
On peut alors simuler l'upcasting :
$c = new Child(); $m = new Person($c);
Un tel besoin peut paraître déroutant, puisque en réalité, une instance de Child est déjà par héritage une instance de Person, à laquelle des spécificités sont apportées. Néanmoins, dans certains cas, il peut s'avérer utile de retirer les atouts d'une instance dérivée pour n'en retrouver que les comportement et propriétés héritées. Par exemple, une méthode qui accepte un objet en paramètre pourrait interdire la réception d'une classe dérivée dont les caractéristiques seraient jugées inopportunes.
class Person
{
public function haveSex(Person $p)
{
if ($p instanceof Child) {
throw new Exception('Tu devrais pas être au lit toi ?');
}
// n'golo golo !
}
}
Finalement, voici comment conclure par un malheureux inceste programmatique ;)
$serge = new Person(); $charlotte = new Child(); $serge->haveSex(new Person($charlotte));
Par soucis de performance, il m'arrive de temps en temps d'exporter le contenu d'une table MySQL pour en créer un tableau PHP associatif. Disposant ainsi des données en mémoire, ceci me permet, par exemple lors d'une requête de sélection, d'épargner une jointure avec cette table. Bien entendu, ceci n'est réellement intéressant que pour les tables de petite taille (table de devises, de pays, etc...)
Malgré la petite taille de ces tables, la procédure pour générer le code du tableau est généralement fastidieuse à moins de disposer d'un petit script "fait maison" sous la main.
J'ai donc décidé de publier un modeste outil utilisable sous la forme d'un plugin pour phpMyAdmin. Il ajoute la fonctionnalité désirée (cf. checkbox "PHP Array") à la liste des formats disponibles pour l'export des bases de données.

Pour l'installation, rien de plus simple. Il suffit de télécharger le plugin ici et d'extraire le fichier PHP dans le répertoire phpMyAdmin/libraries/export/.
Par contre, le script étant toujours en version beta, tout rapport de bug ou suggestion d'amélioration sera vivement apprécié. Merci d'avance !
Intrigué par les algorithmes de compression de données, je me suis penché sur RLE qui est sans conteste l'un des moins complexe à implémenter. Il s'applique aux données qui présentent de longues répétitions d'un même caractère. Le principe consiste à ne conserver qu'un seul caractère de chaque plage auquel on préfixera le nombre réel de répétitions attendues. Par exemple :
AAAABBBBBBCDDDDDEEEEEEEEE (25 octets)devient
4A6B1C5D9E (10 octets)Dans ce cas bien choisi le niveau de compression est intéressant, mais loin d'être systématiquement satisfaisant : l'algorithme s'avère en effet très peu approprié aux données qui ne présentent pas de répétitions suffisantes. Ainsi :
ABCDE (5 octets)devient
1A1B1C1D1E (10 octets)
On voit clairement que RLE ne peut être envisagé que dans des domaines d'application bien précis pour pouvoir en espérer un quelconque bénéfice. Initialement inventé pour compresser les documents scannés en noir et blanc (qui présentent inévitablement de longues plages d'octets "blancs"), on peut l'appliquer au cas typique des images bitmaps formées de grandes zones d'une couleur unie. Ces pixels contigus dont le code couleur est identique se traduiront dans le fichier par une suite consécutive d'octets identiques.
 Pour illustrer ce principe, j'ai testé la compression du fichier bitmap ci-contre. La compression RLE a permi de réduire le poids du fichier de 67.3 Ko à 9.1 Ko, c'est qui est déjà appréciable.
Pour illustrer ce principe, j'ai testé la compression du fichier bitmap ci-contre. La compression RLE a permi de réduire le poids du fichier de 67.3 Ko à 9.1 Ko, c'est qui est déjà appréciable.
Ce qui laisse rêveur, c'est d'imaginer l'inventivité mise en oeuvre par le format PNG, pour arriver avec ce même fichier source à un résultat final d'à peine 400 petits octets !
Ma classe PHP
/**
* "Run-length encoding" algorithm compression class
*
* @author Geoffray Warnants - http://www.geoffray.be/
* @version 1.0
*/
class RLE
{
/**
* Compress a string using RLE
*
* @param string $str
* @return string
*/
public static function encode($str)
{
$encoded = '';
for ($i=0, $l=strlen($str), $cpt=0; $i<$l; $i++) {
if ($i+1<$l && $str[$i]==$str[$i+1] && $cpt<255) {
$cpt++;
} else {
$encoded .= chr($cpt).$str[$i];
$cpt = 0;
}
}
return $encoded;
}
/**
* Uncompress a RLE string
*
* @param string $str
* @return string
*/
public static function decode($str)
{
$decoded = '';
for ($i=0,$l = strlen($str); $i<$l; $i+=2) {
if ($i+1<$l && ord($str[$i]) > 0) {
$decoded .= str_repeat($str[$i+1], 1+ord($str[$i]));
} else {
$decoded .= $str[$i+1];
}
}
return $decoded;
}
}
Avec quelques jours de retard, je viens de tester les améliorations mineures apportées par la toute fraiche release 5.2.9 de PHP, dernière ligne droite avant la très attendue 5.3. Outre les corrections de plusieurs bugs, cette nouvelle version présente une légère amélioration du comportement de la méthode magique __call() vis à vis des méthodes privées et protégées. Ainsi, sous les versions antérieures à 5.2.9, l'exemple suivant se soldait par une toute belle Fatal error: Call to private method Foo::bar() from context ''
<?php
class Foo {
public function __call($method, $args) {
if (method_exists($this, $method)) {
call_user_func_array(array($this, $method), $args);
}
}
private function bar() {
echo 'Hello';
}
}
$foo = new Foo();
$foo->bar();
?>
Bonne nouvelle : cet agaçant comportement que tout un chacun a probablement déjà rencontré fait désormais partie du passé.
A l'école primaire, il m'arrivait souvent de jouer les agents secrets en mettant mes camarades au défi de déchiffrer des messages codés. Un codage utilisé était par exemple de remplacer chacune des lettres par sa précédente dans l'alphabet, rendant ainsi le texte illisible mais facilement déchiffrable par qui en connaissait l'astuce.
Sans le savoir, je venais de mettre en pratique une méthode de chiffrement ancestrale appelée le Chiffre de César en l'honneur à Jules César, son inventeur, qui l'utilisait probablement en son temps pour transmettre ses mots doux en toute discrétion ;-). Un cas particulier de cet algorithme est le ROT13, qui décale chaque caractère alphabétique de 13 positions. Une clé qui n'a pas été choisie sans raison : Considérant notre alphabet de 26 lettres comme une suite circulaire (on revient au A après le Z), appliquer la translation 2 fois de suite permet de retrouver le texte original.
C'est d'ailleurs pourquoi la fonction PHP str_rot13() ne possède tout logiquement pas d'équivalence pour le décodage.
echo str_rot13(str_rot13('La boucle est bouclée'));
Je trouve cet exemple très pertinent pour illustrer que le fait d'appliquer successivement une même fonction d'encodage contribue parfois à affaiblir la robustesse d'un algorithme !
Voulant une fois pour toutes pouvoir gérer correctement les appels à des pages distantes via HTTP, j'ai décidé de me pencher sur la librairie cURL. Une des premières étapes que je souhaitais accomplir était d'extraire les en-têtes HTTP afin d'obtenir une indication sur le déroulement de la requête HTTP demandée. Une première approche permet de réaliser ceci très simplement grâce à l'option de transmission CURLOPT_HEADER :
<?php $url = curl_init(); curl_setopt($url, CURLOPT_URL, 'http://www.google.com'); curl_setopt($url, CURLOPT_RETURNTRANSFER, true); curl_setopt($url, CURLOPT_HEADER, true); $page = curl_exec($url); curl_close($url); ?>
L'inconvénient majeur de cette méthode est que les en-têtes HTTP et le contenu de la page demandée se retrouvent concaténés dans le résultat de curl_exec(). Effectuer une décomposition manuelle du résultat obtenu pourrait fournir le résultat attendu, mais c'est alors omettre une solution plus propre offerte par la librairie. Elle propose en effet un mécanisme de fonctions "callbacks" appelées lorsqu'un évènement particulier se produit. Dans le cas qui nous intéresse ici, l'option CURLOPT_HEADERFUNCTION permet d'appeler une fonction à chaque en-tête HTTP rencontré. Attention que cette fonction doit absolument retourner le nombre d'octets de l'en-tête reçu en paramètre.
<?php
function read_header($url, $str) {
echo 'Header : '.$str."\n";
return strlen($str);
}
$url = curl_init();
curl_setopt($url, CURLOPT_URL, 'http://www.google.com');
curl_setopt($url, CURLOPT_RETURNTRANSFER, true);
curl_setopt($url, CURLOPT_HEADER, true);
curl_setopt($url, CURLOPT_HEADERFUNCTION, 'read_header');
$page = curl_exec($url);
curl_close($url);
?>
Sur base de ce principe, on peut alors se construire rapidement une petit classe, histoire d'encapsuler ces traitements dans un objet :
<?php
/**
* A sample class to read HTTP headers
* @author Geoffray Warnants - http://www.geoffray.be
*/
class HTTPReader {
protected $_url = null;
protected $_headers = array();
protected $_body = '';
public function __construct($url) {
$this->_url = curl_init($url);
curl_setopt($this->_url, CURLOPT_RETURNTRANSFER, true);
curl_setopt($this->_url, CURLOPT_HEADER, true);
curl_setopt($this->_url, CURLOPT_HEADERFUNCTION,
array($this, 'readHeaders')
);
}
public function __destruct() {
curl_close($this->_url);
}
public function getHeaders() {
$this->_body = curl_exec($this->_url);
return $this->_headers;
}
public function getBody() {
return $this->_body;
}
protected function readHeaders($url, $str) {
if (strlen($str) > 0) {
$this->_headers[] = $str;
}
return strlen($str);
}
}
?>
// en Java new Application(login, pwd).start();La particularité est qu'on peut utiliser un objet sans avoir forcément besoin de le déclarer dans une variable. Ceci est souvent utilisé dans le cas où cet objet n'est nécessaire qu'à un unique endroit du programme. Malheureusement, PHP n'autorise pas cette syntaxe, ce qui nous contraint de scinder l'opération et de s'encombrer d'une variable intermédiaire qui nous est inutile.
// en PHP $app = new Application($login, $pwd); $app->start(); unset($app);
L'avantage de la première solution, outre le fait apprécié qu'elle offre une écriture plus concise, réside dans la mise en évidence de l'inutilité de l'instance en dehors de cet unique appel, ce qui peut s'avérer d'une grande utilité pour une compréhension rapide du code par un tierce développeur.
Pour pouvoir reproduire cette écriture en PHP, j'ai créé la petite classe suivante (qui aurait très bien pu n'être qu'une simple fonction) :
class ClassLoader {
public static function load($className, $arg=null) {
$c = new ReflectionClass($className);
return ($c->hasMethod('__construct') || $c->hasMethod($className)) ?
$c->newInstanceArgs(array_splice(func_get_args(), 1)) :
$c->newInstance();
}
}
On peut alors écrire :
ClassLoader::load('Application', $login, $pwd)->start();
Le principe devient intéressant, mais la clarté du code en a pris un sacré coup ! Pour simplifier, j'ai pensé à une nouveauté très attendue de PHP 5.3 : la nouvelle méthode magique __callStatic, dont le comportement est identique à la méthode __call bien connue, mais adaptée aux méthodes statiques.
// à partir de PHP 5.3
class ClassLoader {
public static function __callStatic($method, $args) {
$c = new ReflectionClass($method);
return ($c->hasMethod('__construct') || $c->hasMethod($method)) ?
$c->newInstanceArgs($args) :
$c->newInstance();
}
}
L'écriture gagne ainsi nettement en simplicité :
ClassLoader::Application($login, $pwd)->start();Il ne reste plus qu'à finaliser la classe pour la rendre compatible PHP 5 et 6, ce qui ne pose pas de problème. Il sera juste laissé au développeur le soin de réaliser les appels adéquats selon la version de PHP utilisée, avec la seule petite restriction qu'en PHP 6, le chargement d'une éventuelle classe nommée "Load" devra inévitablement se faire via l'écriture PHP 5.
class ClassLoader {
public static function load($className, $arg=null) {
$c = new ReflectionClass($className);
return ($c->hasMethod('__construct') || $c->hasMethod($className)) ?
$c->newInstanceArgs(array_splice(func_get_args(), 1)) :
$c->newInstance();
}
public static function __callStatic($className, $args) {
return call_user_func_array(
array(self, 'load'), array_merge(array($className),$args)
);
}
}
$path = rtrim($path, '/\\').'/';Pour être pointilleux, on pourrait même pousser le vice jusqu'à utiliser la constante DIRECTORY_SEPARATOR afin de terminer la chaîne par le caractère slash ou backslash adéquat selon le système d'exploitation sur lequel on se trouve :
$path = rtrim($path, '/\\').DIRECTORY_SEPARATOR;J'avoue me contenter généralement de la première solution, bien plus rapide à écrire et qui se révèle tout aussi portable puisque gérée par les principaux OS (Windows, *nix, Mac OS). Cette constante n'est pas pour autant totalement dénuée d'intérêt puisqu'elle peut par exemple trouver son utilité lorsqu'on souhaite traiter un chemin retourné par le système d'exploitation. Il peut donc s'avérer utile de faire :
$path = str_replace(DIRECTORY_SEPARATOR, '/', rtrim(getcwd(), '/\\')).'/';
in_array(0, array('A','B','C')); // Retourne TRUE !!
Cette instruction montre que pour PHP, le nombre 0 se trouve bien dans le tableau ne comportant que des chaînes de caractères.
Bien que cela puisse paraître surprenant, ce comportement est tout à fait normal. Pour le comprendre, il faut se souvenir de la manière dont PHP réalise les comparaisons entre valeurs de types différents.
PHP étant un language faiblement typé, pour pouvoir comparer ce qui est comparable, il doit parfois réaliser implicitement des conversions de type (transtypage, ou casting) sur l'une des 2 opérandes.
Ainsi, dans le cas d'une comparaison nombre/chaîne, il est important de savoir que c'est toujours la chaîne qui est implicitement castée en nombre.
// cette condition sera vérifiée echo (0 == 'A') ? 'TRUE' : 'FALSE'; // car elle est identique à echo (0 == (int)'A') ? 'TRUE' : 'FALSE';Et comme on sait que le casting d'une chaîne non numérique en un nombre retournera tout logiquement la valeur 0, voilà notre condition vérifiée !
Bien entendu, une comparaison stricte à l'aide de l'opérateur "triple égal" nous aurait offert le résultat initialement attendu puisqu'il réalise une comparaison aussi bien les valeurs que sur les types.
// cette condition ne sera pas vérifiée echo (0 === 'A') ? 'TRUE' : 'FALSE';Il faut aussi savoir que la fonction in_array possède elle même le moyen de réaliser cette comparaison stricte car elle accepte un dernier paramètre optionnel qui permet d'activer ou non cette fonctionnalité. Non activée par défaut, il nous aurait fallu écrire dès le départ :
in_array(0, array('A','B','C'), true); // Retourne FALSE
Pour conclure, outre le fait que profiter du confort offert par le faible typage de PHP ne se fait pas sans une extrême vigilance, j'ajouterai qu'avant d'accuser le langage d'un nouveau bug, il est peut-être utile d'envisager une éventuelle défaillance du programmeur ;)
Liens utiles
 Vivement attendue, la release 1.5 du célèbre framework signé Zend Technologies débarque en version finale. Une sortie toute fraiche dont j'attendais impatiemment l'arrivée avant de me lancer dans l'apprentissage de ce framework, choisi après mûre réflexion parmi les nombreux autres prétendants très convaincants qui se bousculent au portillon. Voilà, maintenant plus d'excuses, va falloir s'y mettre !
Vivement attendue, la release 1.5 du célèbre framework signé Zend Technologies débarque en version finale. Une sortie toute fraiche dont j'attendais impatiemment l'arrivée avant de me lancer dans l'apprentissage de ce framework, choisi après mûre réflexion parmi les nombreux autres prétendants très convaincants qui se bousculent au portillon. Voilà, maintenant plus d'excuses, va falloir s'y mettre !
public static function writeArray($aInput, $jsVarName, $eol=PHP_EOL)
{
$js = $jsVarName.'=new Array();'.$eol;
foreach ($aInput as $key => $value) {
if (!is_numeric($key)) {
$key = '"'.$key.'"';
}
if (is_array($value)) {
$js .= self::writeArray($value, $jsVarName.'['.$key.']', $eol);
} else {
if (is_null($value)) {
$value = 'null';
} elseif (is_bool($value)) {
$value = ($value) ? 'true' : 'false';
} elseif (!is_numeric($value)) {
$value = '"'.$value.'"';
}
$js .= $jsVarName.'['.$key.']='.$value.';'.$eol;
}
}
return $js;
}
<?php
$clumsy = new ClumsyTyper();
print_r($clumsy->getMistypedString('sexy''));
?>
Va afficher :
Array (
[0] => zexy
[1] => eexy
[2] => qexy
[3] => dexy
[4] => wexy
[5] => xexy
[6] => szxy
[7] => srxy
[8] => ssxy
[9] => sdxy
[10] => sesy
[11] => sedy
[12] => sewy
[13] => secy
[14] => sext
[15] => sexu
[16] => sexg
[17] => sexh
)
Bien évidemment, certains petits filous auront vite cerné l'utilité de cette classe dans d'autres domaines complètement machiavéliques tels que le typosquatting (ou URL hijacking), la génération massive de mots clés (Massive keyword list), et tout un tas de trucs avec des noms qui font très peur, à essayer avec prudence dans un but purement éducatif, bien entendu !
<<< Articles plus récents | Articles plus anciens >>>
