
Lab Javascript/CSS

Pour ceux qui comme moi, après de longues heures passées devant votre éditeur texte favori, éprouvent parfois une fatigue visuelle manifestée par l'impression d'être gêné par le contraste élevé entre le texte noir et le fond blanc, j'ai récolté une série de thèmes un peu moins agressifs visuellement. Beaucoup sont en réalité des thèmes issus du logiciel Mac TextMate que j'ai adaptés à Notepad++ grâce à cet ingénieux convertisseur.
Pour installer un de ces thèmes, il suffit d'écraser le fichier C:\Documents and Settings\%%USERNAME%%\Application Data \Notepad++\stylers.xml par celui qui vous avez téléchargé, après avoir évidemment effectué une sauvegarde du fichier original pour pouvoir restaurer ultérieurement le thème par défaut.
Amy
Blackboard

Choco
Cobalt
IdleFingers
Lowlight
Minimal Theme
Monoindustrial
Monokai
Pastels_on_dark
PersPolis
Plasticcodewrap
Port_of_Ruby_Blue
Sin_city_(that_yellow_bastard)
.full.png)
Soylent_green
Spacecadet
Spectacular
Starlight
Tek
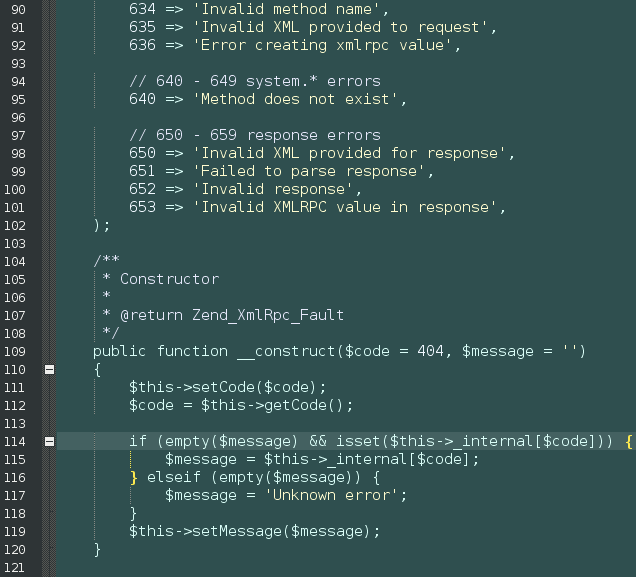
Twilight
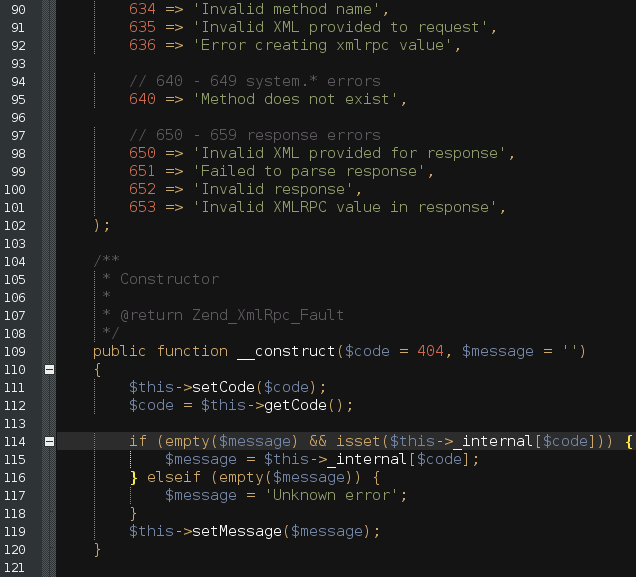
Vibrant_ink
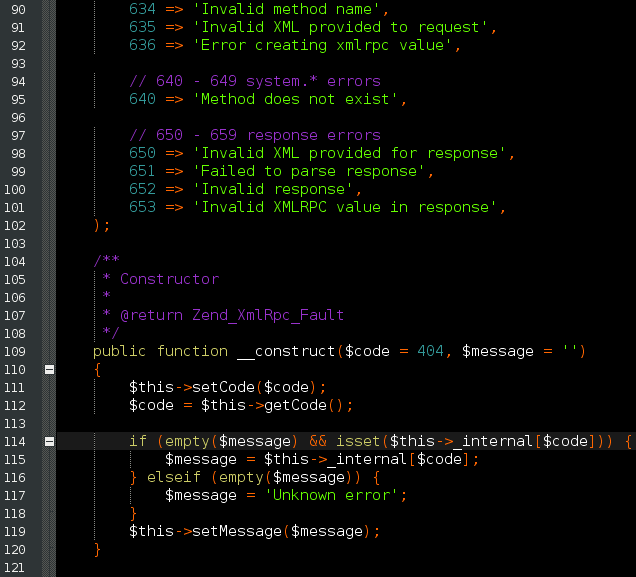
Zenburnesque

Voulant une fois pour toutes pouvoir gérer correctement les appels à des pages distantes via HTTP, j'ai décidé de me pencher sur la librairie cURL. Une des premières étapes que je souhaitais accomplir était d'extraire les en-têtes HTTP afin d'obtenir une indication sur le déroulement de la requête HTTP demandée. Une première approche permet de réaliser ceci très simplement grâce à l'option de transmission CURLOPT_HEADER :
<?php $url = curl_init(); curl_setopt($url, CURLOPT_URL, 'http://www.google.com'); curl_setopt($url, CURLOPT_RETURNTRANSFER, true); curl_setopt($url, CURLOPT_HEADER, true); $page = curl_exec($url); curl_close($url); ?>
L'inconvénient majeur de cette méthode est que les en-têtes HTTP et le contenu de la page demandée se retrouvent concaténés dans le résultat de curl_exec(). Effectuer une décomposition manuelle du résultat obtenu pourrait fournir le résultat attendu, mais c'est alors omettre une solution plus propre offerte par la librairie. Elle propose en effet un mécanisme de fonctions "callbacks" appelées lorsqu'un évènement particulier se produit. Dans le cas qui nous intéresse ici, l'option CURLOPT_HEADERFUNCTION permet d'appeler une fonction à chaque en-tête HTTP rencontré. Attention que cette fonction doit absolument retourner le nombre d'octets de l'en-tête reçu en paramètre.
<?php
function read_header($url, $str) {
echo 'Header : '.$str."\n";
return strlen($str);
}
$url = curl_init();
curl_setopt($url, CURLOPT_URL, 'http://www.google.com');
curl_setopt($url, CURLOPT_RETURNTRANSFER, true);
curl_setopt($url, CURLOPT_HEADER, true);
curl_setopt($url, CURLOPT_HEADERFUNCTION, 'read_header');
$page = curl_exec($url);
curl_close($url);
?>
Sur base de ce principe, on peut alors se construire rapidement une petit classe, histoire d'encapsuler ces traitements dans un objet :
<?php
/**
* A sample class to read HTTP headers
* @author Geoffray Warnants - http://www.geoffray.be
*/
class HTTPReader {
protected $_url = null;
protected $_headers = array();
protected $_body = '';
public function __construct($url) {
$this->_url = curl_init($url);
curl_setopt($this->_url, CURLOPT_RETURNTRANSFER, true);
curl_setopt($this->_url, CURLOPT_HEADER, true);
curl_setopt($this->_url, CURLOPT_HEADERFUNCTION,
array($this, 'readHeaders')
);
}
public function __destruct() {
curl_close($this->_url);
}
public function getHeaders() {
$this->_body = curl_exec($this->_url);
return $this->_headers;
}
public function getBody() {
return $this->_body;
}
protected function readHeaders($url, $str) {
if (strlen($str) > 0) {
$this->_headers[] = $str;
}
return strlen($str);
}
}
?>
Le comportement des navigateurs étant aussi diversifié qu'improbable, il s'avère souvent fort tentant d'user de certains "hacks", autant en CSS qu'en Javascript. Bien que ces pratiques soient à utiliser avec prudence (elles constituent parfois une antorse aux standards du web et pourraient provoquer un comportement inattendu sous les futures versions du navigateur ainsi "patché"), elles permettent de corriger certains comportements étranges et autres problèmes de rendu.
En Javascript, pour mettre en place nos propres traitements alternatifs selon le browser, Mootools, plutôt que de proposer un moyen d'identifier le browser qui interprète la page, propose une détection plus intelligente basée sur le moteur interne du navigateur. Comme la plupart des navigateurs sont fondés sur les mêmes principaux moteurs, il est en effet plus judicieux d'effectuer la distinction sur ce critère. Pour ce faire, il suffit d'interroger quelques propriétés de l'objet Browser pour connaître le moteur de rendu qui interprète la page :
- Browser.Engine.name : (string) Nom du moteur
- Browser.Engine.version : (int) Version du moteur
- Browser.Engine.gecko : (bool) True si le navigateur utilise le moteur Gecko
- Browser.Engine.trident : (bool) True si le navigateur utilise le moteur Trident
- Browser.Engine.webkit : (bool) True si le navigateur utilise le moteur WebKit
- Browser.Engine.presto : (bool) True si le navigateur utilise le moteur Presto
Un rapide petit test executé sur une panoplie de navigateurs (merci BrowserShots) m'a permi d'établir le tableau récapitulatif suivant :
| Browser.Engine | ||||||
|---|---|---|---|---|---|---|
| .name | .version | .gecko | .trident | .webkit | .presto | |
| Firefox 1.5 | gecko | 18 | true | undefined | undefined | undefined |
| Firefox 2.0 | gecko | 18 | true | undefined | undefined | undefined |
| Firefox 3.0 | gecko | 19 | true | undefined | undefined | undefined |
| Firefox 3.1 | gecko | 19 | true | undefined | undefined | undefined |
| Seamonkey 1.1 | gecko | 18 | true | undefined | undefined | undefined |
| Seamonkey 2.0 | gecko | 19 | true | undefined | undefined | undefined |
| Camino 1.6 | gecko | 18 | true | undefined | undefined | undefined |
| Galeon 2.0 | gecko | 18 | true | undefined | undefined | undefined |
| Navigator 9.0 | gecko | 18 | true | undefined | undefined | undefined |
| Epiphany 2.22 | gecko | 18 | true | undefined | undefined | undefined |
| K-Meleon 1.5 | gecko | 18 | true | undefined | undefined | undefined |
| Flock 1.2 | gecko | 18 | true | undefined | undefined | undefined |
| Flock 2.0 | gecko | 19 | true | undefined | undefined | undefined |
| IE 5.5 | trident | 4 | undefined | true | undefined | undefined |
| IE 6.0 | trident | 4 | undefined | true | undefined | undefined |
| IE 7.0 | trident | 5 | undefined | true | undefined | undefined |
| IE 8.0 | trident | 5 | undefined | true | undefined | undefined |
| Avant 11.7 | trident | 5 | undefined | true | undefined | undefined |
| Konqueror 3.5 | webkit | 419 | undefined | undefined | true | undefined |
| Safari 2.0 | webkit | 419 | undefined | undefined | true | undefined |
| Safari 3.2 | webkit | 525 | undefined | undefined | true | undefined |
| Safari 4.0 | webkit | 525 | undefined | undefined | true | undefined |
| Chrome 0.3 | webkit | 525 | undefined | undefined | true | undefined |
| Chrome 1.0 | webkit | 525 | undefined | undefined | true | undefined |
| Opera 8.53 | presto | 925 | undefined | undefined | undefined | true |
| Opera 9.52 | presto | 950 | undefined | undefined | undefined | true |
| Opera 9.62 | presto | 960 | undefined | undefined | undefined | true |
| Opera 10.0 | presto | 960 | undefined | undefined | undefined | true |
Un mécanisme similaire existe aussi pour détecter le système d'exploitation, mais cette fois sans permettre d'en distinguer les versions.
| Browser.Platform | ||||||
|---|---|---|---|---|---|---|
| .name | .win | .linux | .mac | .ipod | .other | |
| Windows | win | true | undefined | undefined | undefined | undefined |
| Linux | linux | undefined | true | undefined | undefined | undefined |
| Mac | mac | undefined | undefined | true | undefined | undefined |
| iPod | ipod | undefined | undefined | undefined | true | undefined |
| Autres (BSD, ...) | other | undefined | undefined | undefined | undefined | true |
// en Java new Application(login, pwd).start();La particularité est qu'on peut utiliser un objet sans avoir forcément besoin de le déclarer dans une variable. Ceci est souvent utilisé dans le cas où cet objet n'est nécessaire qu'à un unique endroit du programme. Malheureusement, PHP n'autorise pas cette syntaxe, ce qui nous contraint de scinder l'opération et de s'encombrer d'une variable intermédiaire qui nous est inutile.
// en PHP $app = new Application($login, $pwd); $app->start(); unset($app);
L'avantage de la première solution, outre le fait apprécié qu'elle offre une écriture plus concise, réside dans la mise en évidence de l'inutilité de l'instance en dehors de cet unique appel, ce qui peut s'avérer d'une grande utilité pour une compréhension rapide du code par un tierce développeur.
Pour pouvoir reproduire cette écriture en PHP, j'ai créé la petite classe suivante (qui aurait très bien pu n'être qu'une simple fonction) :
class ClassLoader {
public static function load($className, $arg=null) {
$c = new ReflectionClass($className);
return ($c->hasMethod('__construct') || $c->hasMethod($className)) ?
$c->newInstanceArgs(array_splice(func_get_args(), 1)) :
$c->newInstance();
}
}
On peut alors écrire :
ClassLoader::load('Application', $login, $pwd)->start();
Le principe devient intéressant, mais la clarté du code en a pris un sacré coup ! Pour simplifier, j'ai pensé à une nouveauté très attendue de PHP 5.3 : la nouvelle méthode magique __callStatic, dont le comportement est identique à la méthode __call bien connue, mais adaptée aux méthodes statiques.
// à partir de PHP 5.3
class ClassLoader {
public static function __callStatic($method, $args) {
$c = new ReflectionClass($method);
return ($c->hasMethod('__construct') || $c->hasMethod($method)) ?
$c->newInstanceArgs($args) :
$c->newInstance();
}
}
L'écriture gagne ainsi nettement en simplicité :
ClassLoader::Application($login, $pwd)->start();Il ne reste plus qu'à finaliser la classe pour la rendre compatible PHP 5 et 6, ce qui ne pose pas de problème. Il sera juste laissé au développeur le soin de réaliser les appels adéquats selon la version de PHP utilisée, avec la seule petite restriction qu'en PHP 6, le chargement d'une éventuelle classe nommée "Load" devra inévitablement se faire via l'écriture PHP 5.
class ClassLoader {
public static function load($className, $arg=null) {
$c = new ReflectionClass($className);
return ($c->hasMethod('__construct') || $c->hasMethod($className)) ?
$c->newInstanceArgs(array_splice(func_get_args(), 1)) :
$c->newInstance();
}
public static function __callStatic($className, $args) {
return call_user_func_array(
array(self, 'load'), array_merge(array($className),$args)
);
}
}
$path = rtrim($path, '/\\').'/';Pour être pointilleux, on pourrait même pousser le vice jusqu'à utiliser la constante DIRECTORY_SEPARATOR afin de terminer la chaîne par le caractère slash ou backslash adéquat selon le système d'exploitation sur lequel on se trouve :
$path = rtrim($path, '/\\').DIRECTORY_SEPARATOR;J'avoue me contenter généralement de la première solution, bien plus rapide à écrire et qui se révèle tout aussi portable puisque gérée par les principaux OS (Windows, *nix, Mac OS). Cette constante n'est pas pour autant totalement dénuée d'intérêt puisqu'elle peut par exemple trouver son utilité lorsqu'on souhaite traiter un chemin retourné par le système d'exploitation. Il peut donc s'avérer utile de faire :
$path = str_replace(DIRECTORY_SEPARATOR, '/', rtrim(getcwd(), '/\\')).'/';
